Thank you to the Quantum Record for sharing some of their thoughts and insight in our knowledge base.
Click here to read this blog on their website.
.png "image(303).png")
By James Myers
There is a tremendous amount of human data for machine learning models, like OpenAI’s ChatGPT, to train on. The supply of human data is, however, not infinite, and machine learning consumes vast amounts of data at great speed.
How soon will chatbots like OpenAI’s ChatGPT, Google’s Gemini, and Microsoft’s Copilot, run out of human training data and be left with only their own outputs to “learn” from – and what will that mean for their subsequent outputs and the humans who have come to rely on them?
At the core of the issue is maintaining a fundamental human superpower we at The Quantum Record have repeatedly highlighted: our imagination, which endows us with the capacity for reason and critical thinking. Each of us has a unique story to tell, which is a powerful message from acclaimed Sapiens author Yuval Harari, and it’s the story that we must tell with our own words and voices.
In her YouTube channel, physicist Sabine Hossenfelder comments on a November 2023 study entitled “The Curious Decline in Linguistic Diversity: Training Language Models on Synthetic Text,” by Yanzhu Guo and co-authors. The researchers point to a decrease of variability in the language output by chatbots, particularly for complex story-telling tasks, when they are recursively trained on their own data. The result is increasingly standardized outputs that we might begin to see as stereotypes of the human data that formed the initial training dataset.
“What are the consequences?” Dr. Hossenfelder asks. “Well, no one really knows. The issue is that our entire environment is basically being contaminated by AI-generated content and since there’s no way to identify its origin, it will inevitably leak into training data. It’s like plastic pollution, it won’t be long until we all eat and breathe the stuff.” She identifies three possible future avenues for generative AI: one is that it will require human creativity, another is that laws will enforce the watermarking of AI-generated content, and the third is that the algorithms will be revised to enforce randomness in their outputs.
Valuing the Future: What’s Good for Human Creativity is Also Good for Financial Investments in AI
Telling our own stories is not only good for preserving human creative unpredictability, it’s also ultimately good for AI companies like OpenAI, Google, and Microsoft that use our data to generate predictions for what we will do or say next. To be sure, there is tremendous profit to be made from generative AI as it currently exists, but if it causes us to become too predictable then the AI’s future value will decrease – potentially very rapidly.
What value would remain for a generative AI whose outputs we human users follow line by line with little or no variability from the present to the future? It would be as if the AI was programming us instead of the reverse.
If the value of money didn’t increase over time, there would be little motivation to invest, and AI companies are now investing heavily in the hope of significant future payoffs from the money they put at risk today. For example, Microsoft has invested $10 billion in OpenAI’s generative AI technology, with the potential for a 100-fold increase in its future value (or maybe less, since OpenAI hasn’t disclosed what return Microsoft has been promised). What future value will there be for Microsoft if OpenAI’s technology fails to generate anything new in the future, and its outputs are predictable repeats of the past?
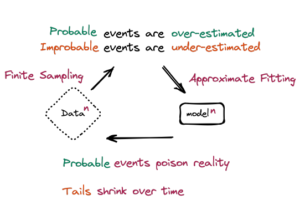
The term “model collapse” has been coined for the outcome of machine learning from data produced by other AI data models. Model collapse is described as “a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time.”
The questions surrounding model collapse are gaining attention and highlight the importance of developing guidelines for the responsible use and consumption of machine learning and its outputs. The concern is amplified by a recent mathematical proof that machine learning algorithms can’t be programmed to maintain a stable output with future certainty in the absence of human intervention to correct the AI’s measurements of probabilities.
An AI reads the study by Weixin Liang and co-authors
One example of emerging issues for model collapse is with peer reviews, in which subject matter experts independently evaluate the scientific work and findings of others. Peer reviews provide an important basis for establishing credibility and guarding against biases and errors, with publishing decisions often hinging on a work passing the peer review process. A case study published this month by Weixin Liang and co-authors suggested that between 6.5% and 16.9% of text submitted as peer reviews after the release of ChatGPT and other large language models “could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates.”
The risk of manipulation and error in AI-generated “peer” reviews reduces their value to humans who have come to rely on them. The study’s authors noted a marked increase in the use of superlative adjectives in reviews, such as “commendable,” “unique,” “intriguing,” “compelling,” “meticulous,” and “intricate,” which tend to magnify the value of the work being reviewed. They observed a particular spike of superlatives in reviews submitted within three days of a deadline. Their conclusions suggest that ChatGPT and other AI-generated or modified content is being used to advance academic status and economic value, and to circumvent time pressures.
For instance, in reviews for one of the largest AI gatherings, the International Conference on Learning Representations (ICLR), the researchers noted a more than 500% increase in the use of the word “innovative” in reviews from 2022 to 2024. OpenAI’s GPT-3 was released to international fanfare in November, 2022, prior to which the word “innovative” consistently appeared in less than 20 per 100 million words. In the first three months of 2024, “innovative” appeared in more than 100 words per 100 million.
Advancing Human Ability to Detect Machine-Generated Stereotypes of Us
As AI-generated content continues to adopt human patterns in expression, it becomes increasingly convincing and our ability to detect its origin decreases. The traceability of data sources is among the prime reasons that many are calling for the watermarking of AI-generated content. It is a subject under consideration by the European Parliament and other regulators, and one in which some advances have been made, for example in the passage of the European Union’s new AI Act.
A May 2023 study by Ilia Shumailov and co-authors entitled “The Curse of Recursion: Training on Generated Data Makes Models Forget” observed that the “use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear.” They conclude that the defects have to be “taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.”
Consider, for example, the following trend to stereotyping:


In calling for strict standards for watermarking of AI-generated content, neuroscientist Erik Hoel wrote in The New York Times, “Isn’t it possible that human culture contains within it cognitive micronutrients — things like cohesive sentences, narrations and character continuity — that developing brains need? Einstein supposedly said: “If you want your children to be intelligent, read them fairy tales. If you want them to be very intelligent, read them more fairy tales.” But what happens when a toddler is consuming mostly A.I.-generated dream-slop? We find ourselves in the midst of a vast developmental experiment.”
On reading Hoel’s words, we should take a moment – or perhaps quite a few moments – to reflect on our own individually unique childhoods. Children can be especially creative and inventive, in their wondering about the reasons why things came to be as they are. Childhood is when we begin telling our individual story, and each one of us has a story to tell during our lives. The collective stories of 7.8 billion humans who now share planet Earth are told in every moment of the present.
Nobody wants their story to be entirely predictable – what would be the purpose of that, and all the daily struggle and effort involved in living and making a difference with each passing day?

Who Wants To Be a Stereotype?
If our actions become stereotypical, we leave ourselves no choice. The stereotypes become our bosses.
Many people rail against the idea that a God or gods exist, given that such being or beings are depicted as having written our story before we have a chance to live it. As we mature from children to adults, most of us want to escape the control of our parents so we can create our own stories and choose our own paths in life. Many don’t relish the thought of maturing from the clutches of human parents to find themselves trapped by the dictates of a supernatural dictator.
This is not to say that gods do or don’t exist, which is not for me to judge and the question of their existence is not, in any event, relevant to the point. The point is that we should not want to deprive children of the potential for growth in their thinking, to rob them of their creativity, and to diminish the possibility for their future contributions to the ongoing story that 7.8 billion people are now creating.
The point is that care and responsibility is required to cherish and preserve our human superpower of the imagination and our creative unpredictability.
We have a responsibility to protect human data, for present and future generations. Taking action now to safeguard against model collapse and entrapment by stereotyping is the responsible thing to do – and the AI companies should thank us for doing it to protect the value of their investment in our data.